
결정트리는 어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측 모델입니다. 대표적인 지도학습 분류 모델이며, 스무고개와 같이 질문에 대하여 '예' 또는 '아니오'를 결정하여 다음과 같이 트리 구조를 나타냅니다.
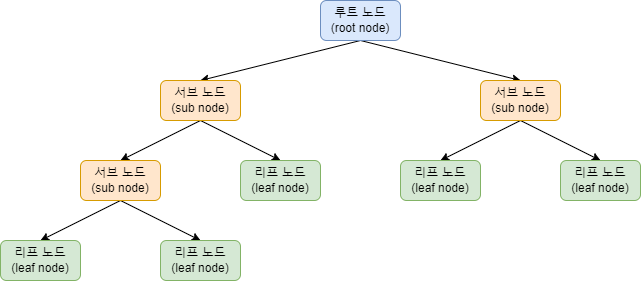
각 기준점을 노드(node) 라고 하며, 첫 분기점을 루트노드(root node), 나머지 분기점을 서브노드(sub node), 마지막 분기점으로 부터 나온 노드를 리프노드(leaf node)라고 합니다.
결정트리의 기본적 아이디어는 복잡도 감소시키는 것에 있습니다. 정보의 복잡도를 불순도(Impurity)라고 하며, 불순도를 수치화한 값에는 지니계수(Gini coefficient)와 엔트로피(Entropy)가 있습니다.
지니계수는 다음과 같습니다.
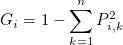
엔트로피는 다음과 같습니다.
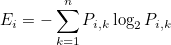
Pi,k는 i번째 노드에 속한 샘플 중 k 클래스에 속한 샘플의 비율을 의미합니다. 예를 들어 빨간 공 6개와 파란공 4개가 섞여있다면 지니계수와 엔트로피는 다음과 같습니다.
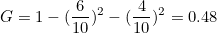
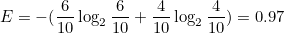
결정트리 알고리즘에는 ID3, CART 등이 있는데 ID3은 엔트로피를 사용하고, CART는 지니계수를 사용하여 분류를 합니다.
1) ID3 알고리즘
ID3 알고리즘은 모든 독립변수가 범주형 데이터인 경우에만 분류가 가능합니다. 정보획득량(Infomation Gain)이 높은 특징부터 분기해나가는데 정보획득량은 분기전 엔트로피와 분기후 엔트로피의 차이를 말합니다.
IG(S, A) = E(S) - E(S|A)
타이타닉 데이터를 통해 알고리즘에 대해 알아보겠습니다.
seaborn 모듈에서 타이타닉 데이터를 불러옵니다. 
범주형 특징만 사용하도록 하겠습니다. 
각 특징에 따른 생존여부(alive)를 분류하고자 합니다. 즉, 'alive'가 루트노드가 됩니다. 우선 루트노드의 엔트로피를 구합니다.
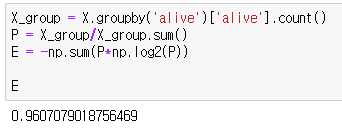
특징별로 정보획득량을 구해야 합니다. 성별을 예를 들면 남성인 경우 생존여부 엔트로피의 비율과 여성인 경우 생존여부 엔트로피 비율을 더합니다.
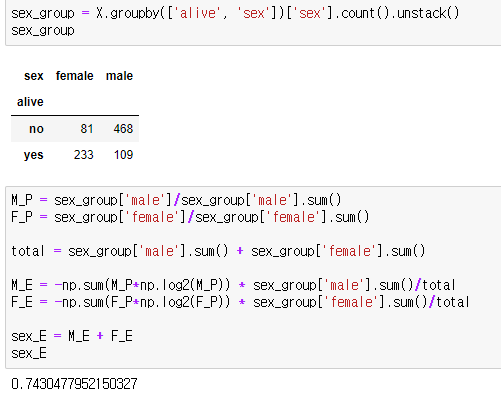
M_E가 남성인 경우 생존여부 엔트로피, F_E가 여성인 경우 생존여부 엔트로피 입니다. 각각의 엔트로피에 성별 비율만큼 곱하여 더하면 특징 'sex'에 대한 생존여부 엔트로피 입니다. 이 값을 전체 생존여부 엔트로피에서 빼면 정보획득량이 됩니다.
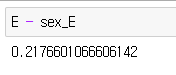
다른 특징도 동일하게 계산하여 정보획득량을 구합니다.
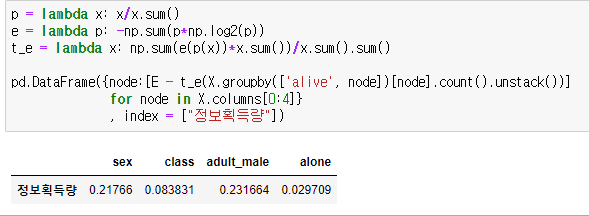
정보획득량이 특징 'adult_male'이 가장 높습니다. 그러므로 첫 분기는 adult_male을 기준으로 분기합니다.
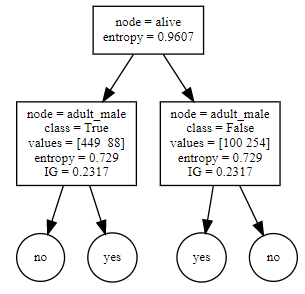
이제 성인인지 아닌지 먼저 분류되었습니다. 이제 성인 노드를 기준으로 다음으로 분기할 특징을 찾아야합니다. 내용은 동일합니다. 성인을 기준으로 하여 각 특징에 대한 생존여부 엔트로피를 구하여 전체 생존여부 엔트로피에서 빼주면 정보획득량이 됩니다.
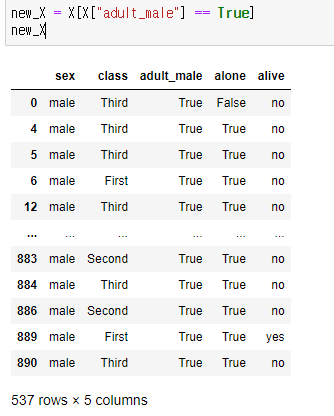
다음과 같이 성인여부가 True인 데이터만 모아서 각 특징에 대한 생존여부의 엔트로피를 구합니다. 그리고 전체 생존여부의 엔트로피에서 빼면 됩니다.
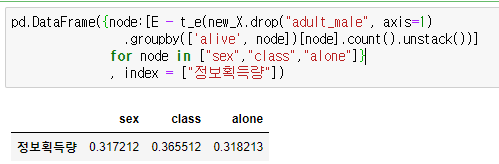
class의 정보획득량이 높습니다. 그러므로 adult_male 노드의 True 클래스에서는 class 노드가 분기됩니다. 이런식으로 반복하면 다음과 같이 됩니다.
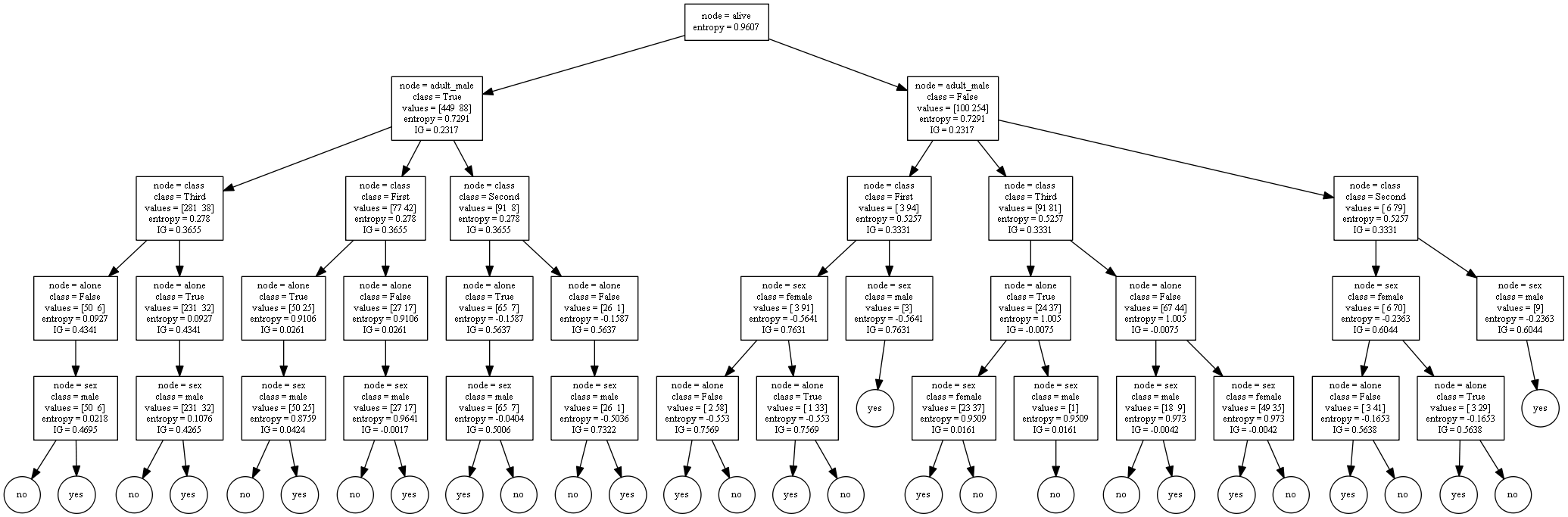
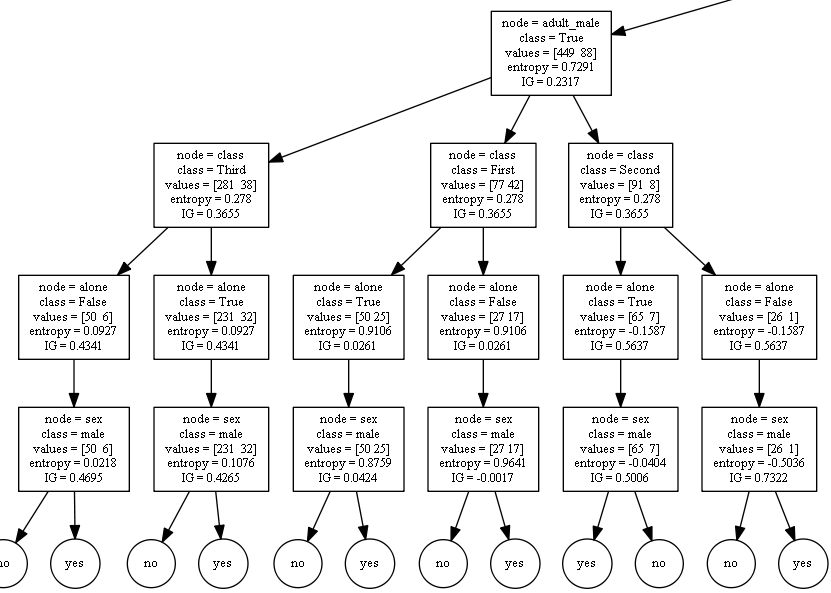
알고리즘이 따로 존재하지 않아 첨부파일에 클래스로 만들어 두었습니다. 아나콘다 환경에서 conda install graphviz 를 입력하여 graphviz 모듈을 설치하고 테스트 해보시면 됩니다. |  스팟
스팟