
pandas는 데이타 분석(Data Analysis)을 위해 널리 사용되는 파이썬 라이브러리 패키지입니다. NumPy 패키지를 기반으로 하며, 인덱스를 가진 1차원 배열 구조 시리즈(Series) 객체와 행 인덱스 및 열 이름을 가진 2차원 배열 구조 데이터 프레임(DataFrame) 객체를 제공합니다.
이번 글에서도 주피터 노트북을 통해 코드를 작성하겠습니다.
우선 numpy 모듈과 pandas 모듈을 import 해주세요. 
1. 시리즈(Series)
시리즈 객체는 1차원 배열 구조를 가지며, 인덱스(index)와 값(values)으로 구성되어 있습니다.
시리즈 객체는 Series 함수를 통해 생성할 수 있습니다. 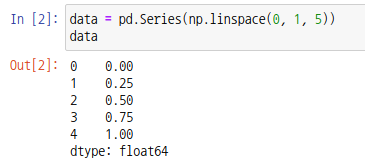
인덱스 배열은 시리즈 객체의 index 속성을 통해 확인가능합니다. 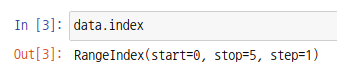
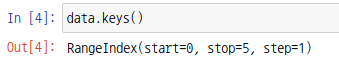
시리즈 객체의 keys 함수를 통해서도 확인가능합니다.
index 파라미터에 값을 설정하여 라벨(label)을 붙여줄 수도 있습니다. 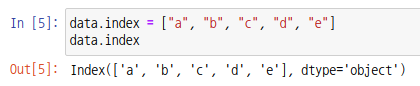
처음부터 매개변수 index를 설정하여 시리즈를 생성할 수도 있습니다. 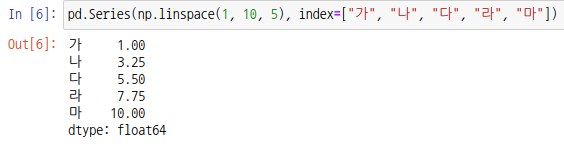
즉, 인덱스는 순서를 나타내는 암묵적 인덱스(implicit index)와, 문자열 라벨을 설정해준 명시적 인덱스(explicit index)가 있습니다. 인덱스 형태가 2가지이기 때문에 인덱서도 2가지가 존재합니다.
암묵적 인덱스는 iloc 인덱서, 명시적 인덱스는 loc 인덱서를 사용합니다. 
암묵적 인덱스와 명시적 인덱스가 겹치지 않는다면 인덱서를 사용하지 않아도 무방합니다. 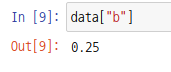
시리즈 객체에서 값 배열은 values 속성을 통해 확인가능합니다. 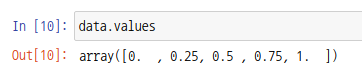
시리즈 객체도 일종의 배열이기때문에 인덱싱, 슬라이싱, 마스킹 등이 가능합니다. 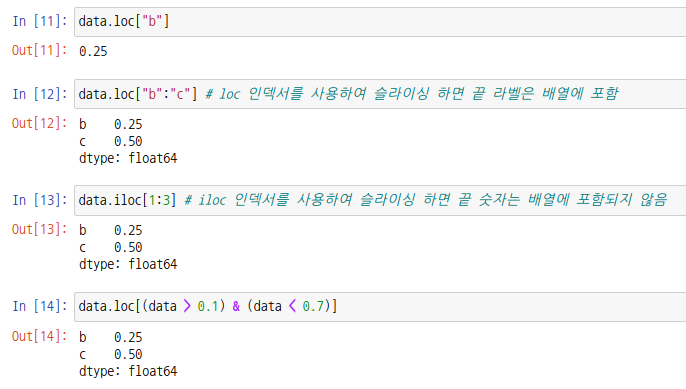
시리즈 객체의 items 함수는 인덱스와 값의 튜플쌍 배열을 출력합니다. 
인덱스를 제거하려면 시리즈 객체의 drop 함수를 사용합니다. 객체에서 인덱스를 제거하는 것이 아니라 해당 인덱스를 제외한 시리즈 객체를 출력하므로 다음과 같이 data 변수에 대입해주세요. 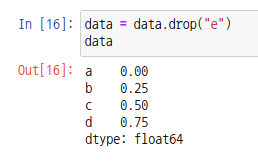
NumPy 기반이기 때문에 범용함수의 사용도 가능합니다. 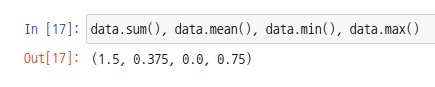
2. 데이터 프레임(DataFrame)
데이터 프레임 객체는 2차원 배열 구조를 가지며, 시리즈의 배열로 구성됩니다. 인덱스(index)와 열(column), 값(values)으로 구성되어 있습니다. 인덱스는 행(row)을 나타냅니다.
데이터 프레임 객체는 DataFrame 함수를 통해 생성할 수 있습니다. 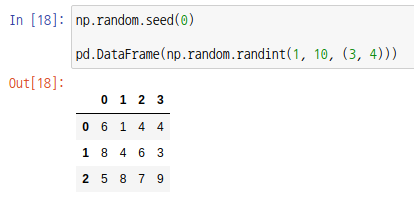
시리즈처럼 처음부터 매개변수를 설정하여 index와 columns를 지정해 줄 수 있습니다.
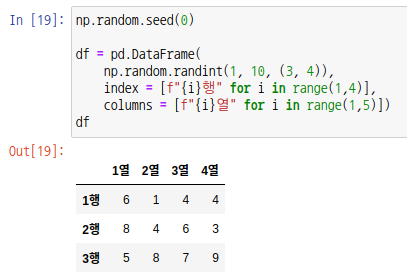
또한 시리즈처럼 인덱싱, 슬라이싱, 마스킹 등이 가능합니다. 데이터 프레임은 시리즈의 배열이기 때문에 인덱서 없이 인덱싱을 하면 해당 열의 시리즈가 출력됩니다. 즉, 열이 1차, 행이 2차입니다.
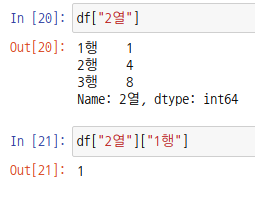
반면, 인덱서를 사용하면 행이 1차, 열이 2차가 됩니다.
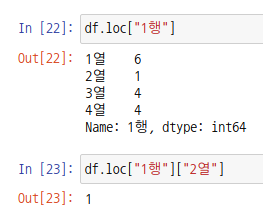
인덱서를 사용하면 numpy 배열처럼 콤마(,)로 구분하여 행렬을 나타낼 수 있습니다. 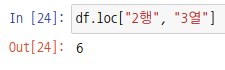
행/열 둘 중 하나가 인덱싱이고 하나는 슬라이싱인 경우 시리즈 객체가 출력됩니다. 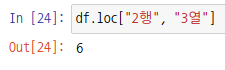
행/열 모두 슬라이싱인 경우 데이터 프레임 객체가 출력됩니다. 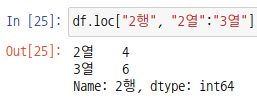
데이터 프레임 객체에 새로운 열을 추가하려면 열 라벨을 키값으로 하여 배열 데이터를 넣어주면 됩니다. 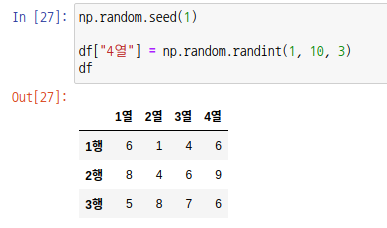
데이터 프레임 객체는 drop 함수도 사용가능합니다. 매개변수로 label, axis, index, columns 등을 가집니다.
axis의 기본값은 0이며, 행방향을 뜻합니다. 즉, 행을 제거합니다. 인덱스나 인덱스 배열을 입력하면 해당 행이 제거됩니다. 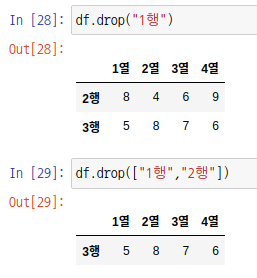
axis를 1로 설정하면 열을 제거하는 것이 가능합니다. 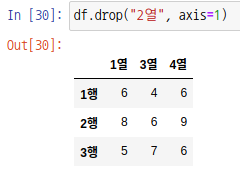
index나 columns를 설정해도 됩니다. 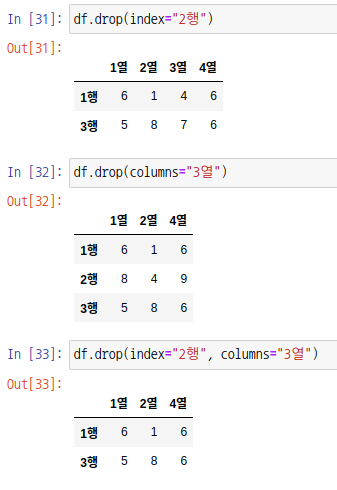
null값을 제거하려면 데이터 프레임 객체의 dropna 함수를 사용합니다. 매개변수 axis를 설정할 수 있는데 생략하면 null값이 있는 행과 열을 제거합니다. axis가 0이면 null값이 있는 행을, 1이면 null값이 있는 열을 제거합니다. 
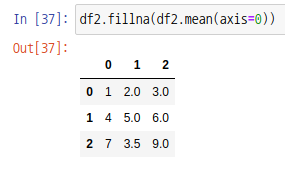
데이터 프레임 객체의 fillna 함수를 통해 null값을 다른 값으로 대체할 수도 있습니다.
데이터 프레임 객체를 조인하려면 merge 함수를 사용합니다. SQL이나 액세스같은 데이터베이스를 조금 아시는 분이라면 조인에 대해서 잘 알것입니다. merge 함수는 매개변수로 left, right, how, on, left_on, right_on 등을 가집니다.
매개변수 left는 왼쪽에 위치할 데이터 프레임, right는 오른쪽에 위치할 데이터 프레임을 입력합니다. 매개변수 how는 조인 방법을 입력합니다. 기본값은 "inner" 입니다. 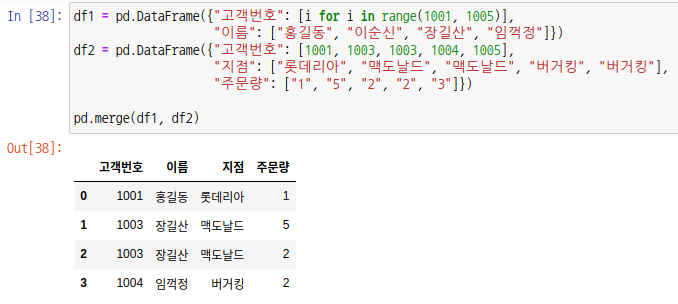
매개변수 how는 inner, outer, right, left, cross를 값으로 가집니다.
inner join은 교집합 부분만 출력합니다. 
df1의 고객번호는 1001 ~ 1004까지 있지만 df2의 고객번호는 1001, 1003, 1004, 1005가 있습니다. 교집합 부분은 1001, 1003, 1004 이므로 이에 해당하는 고객번호 데이터만 출력됩니다.
outer join은 합집합 부분을 출력합니다. 즉, 1001 ~ 1005까지 모든 고객번호의 데이터를 출력합니다. 값이 없으면 NaN 값이 출력됩니다.
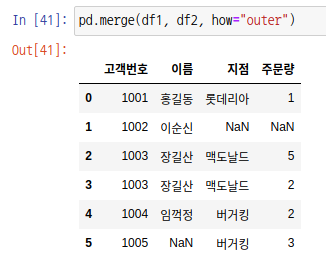
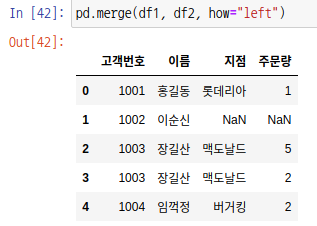
left join은 왼쪽 집합을 기준으로 하는 데이터만 출력합니다. 즉, 고객번호가 1001 ~ 1004인 데이터만 출력합니다. 마찬가지로 값이 없으면 NaN값이 출력됩니다.
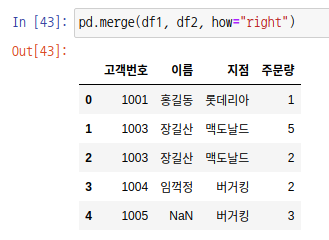
right join은 오른쪽 집합을 기준으로 하는 데이터만 출력합니다. 즉, 고객번호가 1001, 1003, 1004, 1005인 데이터만 출력합니다.
cross join은 모든 행을 조합하여 데이터를 출력합니다. 왼쪽 4행, 오른쪽 5행을 조합하여 20행이 출력됩니다.

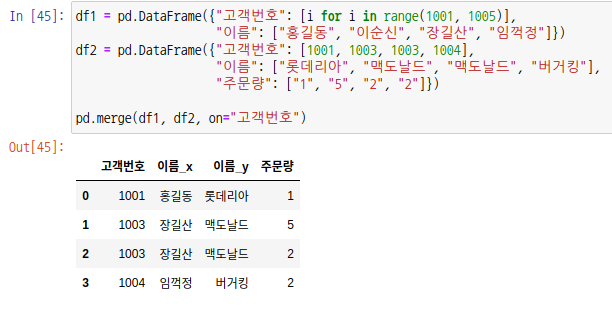
매개변수 on은 기준이 되는 열 라벨을 입력합니다. 생략하면 동일한 라벨을 가진 모든 열이 대상이 됩니다. 라벨이 같지만 기준이 아닌 열은 _x, _y 라는 접미사가 붙습니다.
기준이 되는 열 라벨이 동일하지 않다면 매개변수 left_on, right_on에 열 라벨을 입력합니다. 여기서는 고객번호와 ID가 동일하므로 ID를 drop 함수를 사용하여 제거하면 됩니다.
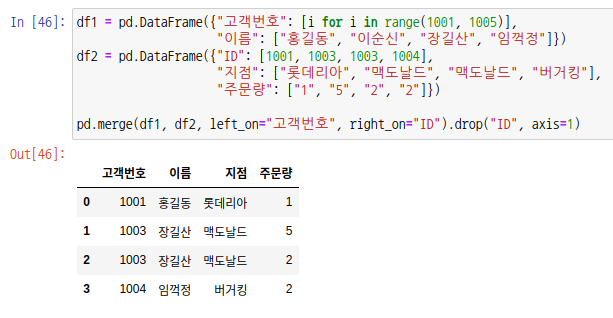
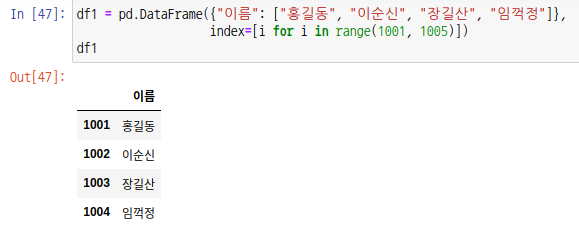
인덱스를 기준으로 조인하고 싶다면 left_index, right_index를 True로 입력합니다. 예시를 위해 인덱스를 1001 ~ 1004까지 설정하여 df1 데이터 프레임을 생성합니다.
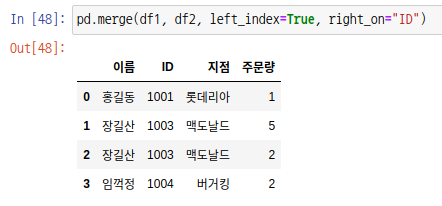
매개변수 left_index를 True로 설정하고 right_on을 "ID"로 설정하여 left join을 해봅시다.
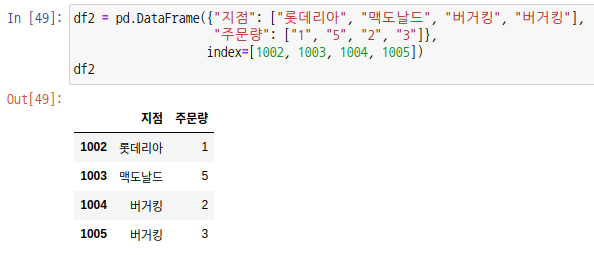
이번에는 인덱스를 1002 ~ 1005까지 설정하여 df2 데이터 프레임을 생성합니다.
매개변수 left_index와 right_index를 True로 설정하여 left join을 해봅시다. 
이번에는 데이터를 정렬해보도록 하겠습니다. seaborn 이라는 시각화 패키지에 예제로 포함된 데이터셋을 사용하겠습니다.
데이터 값을 이용하여 정렬하려면 sort_values 함수를 사용합니다 매개변수는 by, ascending 등을 가집니다. 매개변수 by는 정렬 기준이 되는 열을 설정합니다. 매개변수 ascending은 오름차순으로 정렬할지를 설정합니다. 기본값은 True 입니다. 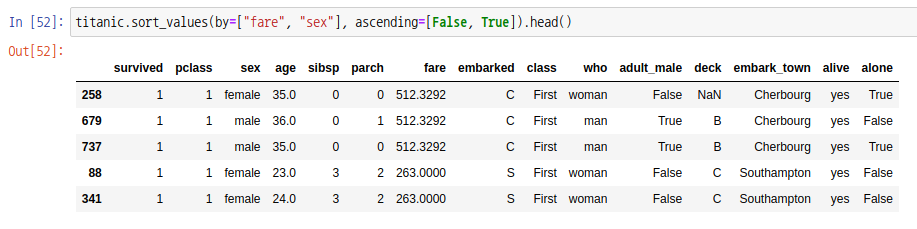
데이터 프레임 객체의 groupby 함수는 열(column)을 인덱스(index)로 묶어 그룹연산을 가능하게 합니다. 매개변수 by에는 인덱스로 사용할 열(column) 라벨을 입력합니다. 우선 성별로 그룹을 만들고 남성과 여성의 생존자수를 확인해보겠습니다.
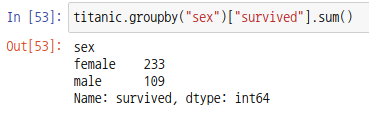
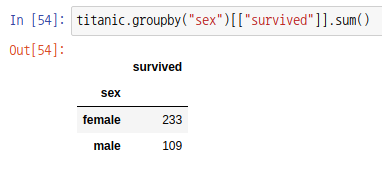
그룹 객체도 시리즈의 배열로 구성되어 있기때문에 시리즈 객체로 출력됩니다. 데이터 프레임 객체로 출력하기 위해서 다음과 같이 배열을 인덱싱해주세요.
생존률은 mean 함수를 사용합니다.
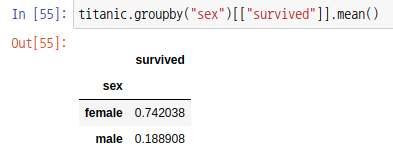
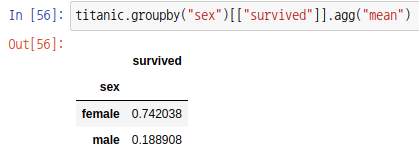
agg 또는 aggregate 함수를 사용해도 동일한 결과가 나옵니다.
시리즈와 데이터 프레임은 stack 함수를 통해 열(column)을 인덱스(index)로 변경하거나 unstack 함수를 통해 인덱스(index)를 열(column)로 변경할 수 있습니다.
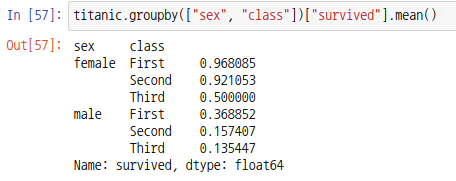
다음과 같이 성별과 클래스를 인덱스를 그룹으로 하여 생존률을 시리즈로 출력할 수 있습니다.
이제 unstack 함수를 통해 "class" 인덱스(index)를 열(column)로 변경하면 다음과 같이 데이터 프레임이 출력됩니다.
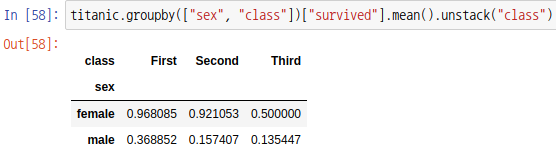
매개변수를 생략하면 가장 오른쪽에 있는 행 인덱스가 열 라벨로 변경되므로 동일한 결과를 얻습니다.
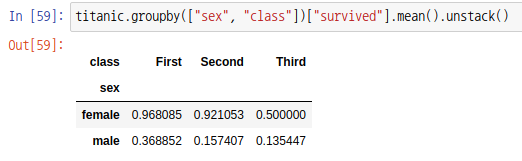
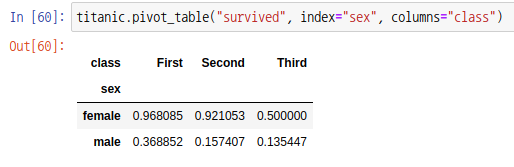
pivot_table 함수를 통해서도 위와 같은 피벗 테이블을 만들 수 있습니다.
|  스팟
스팟