
1. 머신러닝(Machine Learning)이란?
머신러닝(Machine Learning)은 명시적으로 규칙을 프로그래밍하지 않고 데이터로부터 패턴을 스스로 학습하는 것을 말하며, 인공지능의 하위로 분류됩니다.
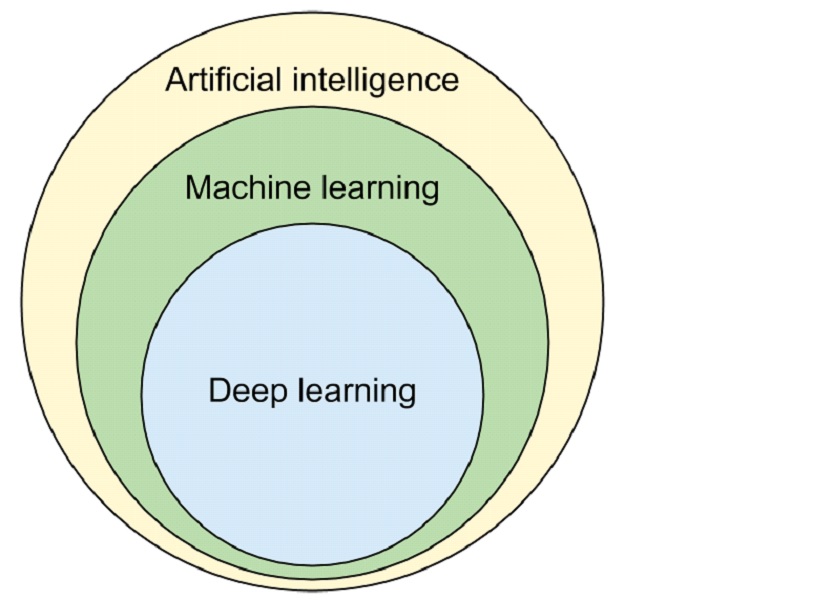
인공지능(Artificial Intelligence, AI)이란 인간이 가지고 있는 지적 능력을 컴퓨터에서 구현하는 다양한 기술이나 소프트웨어, 컴퓨터 시스템 등을 통틀어 일컫습니다.
전통적인 인공지능 프로그래밍은 인간이 직접 알고리즘을 작성하여 입력값과 조건에 의하여 출력값이 나오는 반면, 머신러닝은 입력값과 출력값을 통해 컴퓨터가 스스로 학습하여 알고리즘을 생성합니다. 생성된 알고리즘을 통해 새로운 입력값에 대한 출력값을 예측할 수 있습니다.
딥러닝(Deep Learning)은 머신러닝의 한 종류입니다. 사람의 뇌는 뉴런의 시냅스를 통해 신호를 주고 받는것 만으로도 다양한 사고를 합니다. 이를 모방하여 딥러닝은 여러 층의 인공신경망(Artificial Neural Network, ANN)을 통해 심층학습을 합니다.

기존 머신러닝은 사람이 특징(feature)을 추출하여 기계에게 알려줌으로써 학습을 수행했지만 딥러닝은 기계 스스로 특징을 추출하여 학습을 합니다. 쉽게 말하자면, 기존 머신러닝은 여러장의 사진을 주고 "강아지와 고양이로 분류해라" 라는 가이드라인을 주어야 분류를 하지만, 딥러닝은 가이드라인 없이 스스로 사진을 강아지와 고양이로 분류합니다.
2. 머신러닝을 사용하는 이유
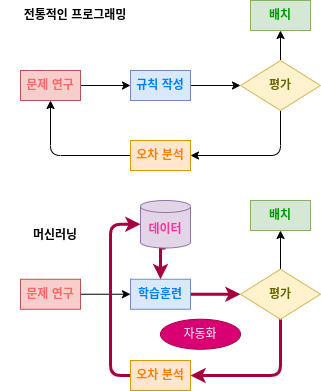
위의 사진처럼 전통적인 프로그래밍의 경우 오차가 있으면 규칙을 다시 작성해야 하며, 오차가 많을수록 프로그래밍 코드가 길고 복잡해지면서 유지 및 보수 비용이 증가하게 됩니다. 반면 머신러닝의 경우 사람이 직접 알고리즘을 작성할 필요가 없으므로 프로그래밍 코드 길이가 상대적으로 짧아지고 대량의 데이터로 반복적인 학습훈련을 통해 분류의 정확도가 높아집니다. 또한 오차가 있으면 데이터를 업데이트하여 학습훈련 함으로써 알고리즘을 자동으로 수정하므로 사람의 개입이 필요없고, 만들어진 알고리즘을 분석하여 인간이 알지 못했던 새로운 규칙을 발견할 수도 있습니다.
3. 머신러닝의 종류
머신러닝은 크게 지도학습, 비지도학습, 강화 학습으로 나눠집니다.
1) 지도 학습(Supervised Learning)
지도 학습은 입력(특징행렬)과 출력(레이블 데이터) 쌍이 제공되면 학습을 통해 규칙을 찾아내는 것입니다. 여기에는 크게 분류(classification) 모델과 회귀(Regression) 모델로 구분됩니다.
분류(classification) 모델은 범주형 데이터인 레이블을 예측할 때 사용합니다. 예를 들어 ["A", "B", "C"] 라는 레이블 데이터를 통해 학습한다면 새로운 입력이 있을때 출력되는 레이블은 항상 "A", "B", "C" 중 하나가 됩니다. 대표적인 알고리즘으로 K-최근접 이웃(K-NN), 로지스틱 회귀, 서포트 벡터 머신(SVM), 의사 결정 트리 등이 있습니다.
회귀(Regression) 모델은 연속형 수치 데이터인 레이블을 예측할 때 사용합니다. 통계학의 회귀분석 기법 중 선형회귀 기법이 이에 해당합니다.
2) 비지도 학습(Unsupervised Learning)
비지도 학습은 레이블 없이 특징행렬만을 통해 규칙을 찾아내는 것입니다. 통계학의 군집화(Clustering)나 연관규칙(Association rule), 차원축소 등과 관련있습니다.
3) 강화 학습(Reinforcement Learning)
강화 학습은 어떤 환경 안에서 정의된 주체(agent)가 현재의 상태(state)를 관찰하여 선택할 수 있는 행동(action)들 중에서 가장 최대의 보상(reward)을 가져다주는지 행동이 무엇인지를 학습하는 것입니다.
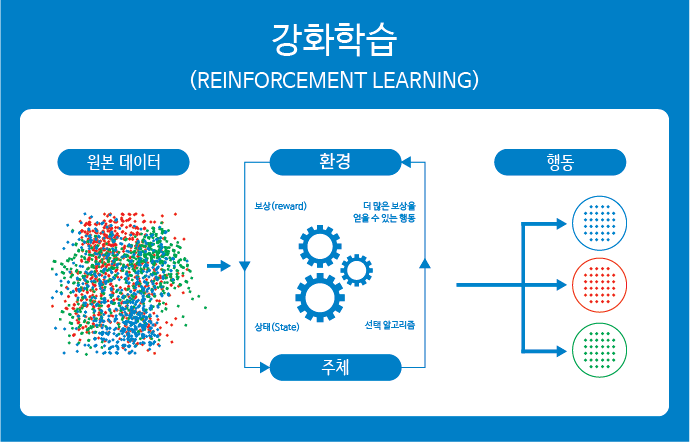
출처: http://www.tcpschool.com/deep2018/deep2018_machine_reinforcement
정의된 주체(agent)가 주어진 환경(environment)의 현재 상태(state)를 관찰(observation)하여, 이를 기반으로 행동(action)을 취하면 주체는 보상(reward)을 받습니다. 이 보상을 기반으로 정의된 주체는 더 많은 보상을 얻을 수 있는 방향(best action)으로 행동을 학습하게 됩니다.
환경으로부터 보상을 받아 학습을 반복하는 것이 지도학습과 비슷해보이지만 사람으로 부터 받는 것이 아니라는 차이점이 있습니다. 시행착오를 통해 학습하는 것이 인간과 매우 유사하여 인공지능을 가장 잘 대표하는 모델입니다. 알파고도 강화 학습을 통해 학습한 것으로 알려져 있습니다.
4. 머신러닝 개발환경 구축
머신러닝은 파이썬을 통해 개발할 수 있습니다. numpy, pandas, scipy, matplotlib, seaborn, scikit-learn 등 많은 라이브러리가 필요한데 아나콘다(anaconda)라는 파이썬 배포판을 통해 환경을 설정하도록 하겠습니다.
https://www.anaconda.com/products/individual 로 이동하여 os에 맞는 설치파일을 다운로드 하세요.
저는 리눅스를 기준으로 설명하겠습니다.
다운받은 설치파일(Anaconda3-2021.11-Linux-x86_64.sh)을 터미널에서 bash로 실행합니다.
$ bash ./Anaconda3-2021.11-Linux-x86_64.sh |
Please, press ENTER to continue 메시지가 뜨면 엔터를 누르세요. 
엔터를 계속 누르거나 F를 눌러 Do you accept the license terms? [yes|no] 메시지가 뜨면 yes를 입력하고 엔터를 누릅니다.
아래와 같이 뜨면 엔터를 눌러 설치를 계속 진행시킵시다. 계정폴더 아래 anaconda3 폴더에 설치가 됩니다.
설치가 완료되고 초기화 할꺼냐는 메시지가 뜨면 yes를 입력하고 엔터를 누릅니다. 
터미널을 닫고 다시 열면 base 가상환경이 활성화됩니다. 가상환경을 수동으로 활성화하려면 다음 명령어를 입력한 후 터미널을 다시 엽시다.
$ conda config --set auto_activate_base false |
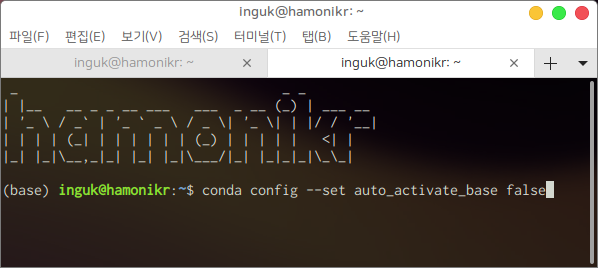
가상환경을 생성하려면 다음 명령어를 입력합니다.
$ conda create -n [가상환경 이름] python=[파이썬 버전] [의존성 패키지] |
저는 ml_py39라는 이름의 가상환경을 만들겠습니다. 가상환경의 파이썬 버전은 3.9로 하고 anaconda 패키지를 설치하도록 합니다.
$ conda create -n ml_py39 python=3.9 anaconda |
작업공간을 만들고 들어가세요.
$ mkdir ~/ml_ws && cd ~/ml_ws |
생성된 가상환경을 활성화 하려면 다음 명령어를 입력합니다.
$ conda activate [가상환경 이름] |
터미널에서 파이썬 자체를 실행해도 되지만 주피터 노트북(jupyter notebook)을 사용하여 코딩하도록 하겠습니다. 주피터 노트북은 웹브라우저 상에서 코드를 단계적으로 실행하도록 할 수 있는 강력한 프로그램입니다. 아나콘다 패키지 설치시 포함되어 있으므로 따로 설치할 필요 없습니다. 다음 명령어를 통해 설정파일을 생성하세요.
$ jupyter notebook --generate-config |
계정폴더 아래 .jupyer 폴더가 숨김파일로 생성됩니다. 다음 명령어를 통해 해당 폴더에 있는 설정파일을 엽니다.
$ xed ~/.jupyter/jupyter_notebook_config.py |
서버 포트를 변경하려면 다음 부분을 검색하여 찾습니다.
# c.NotebookApp.port = 8888 |
앞에 #을 제거하고 원하는 포트로 설정합니다.
c.NotebookApp.port = 18888 |
저장후 다음 명령어로 주피터 노트북을 실행하세요. 설정된 포트를 주소로 하여 자동으로 페이지가 열립니다. 
|  스팟
스팟